| 示例 |
| 正则表达式示例 |
| 数字范围 |
| 浮点数 |
| 电子邮件地址 |
| IP 地址 |
| 有效日期 |
| 数字日期到文本 |
| 信用卡号 |
| 匹配完整行 |
| 删除重复行 |
| 编程 |
| 两个相邻单词 |
| 陷阱 |
| 灾难性回溯 |
| 太多重复 |
| 拒绝服务 |
| 使所有内容可选 |
| 重复捕获组 |
| 混合 Unicode 和 8 位 |
| 本网站上的更多内容 |
| 简介 |
| 正则表达式快速入门 |
| 正则表达式教程 |
| 替换字符串教程 |
| 应用程序和语言 |
| 正则表达式示例 |
| 正则表达式参考 |
| 替换字符串参考 |
| 书评 |
| 可打印 PDF |
| 关于本网站 |
| RSS Feed 和博客 |

失控的正则表达式:灾难性回溯
考虑正则表达式 (x+x+)+y。在你惊恐地大叫并说这个虚构的示例应该写成 xx+y 或 x{2,}y 以完全匹配相同的内容,而无需那些可怕的嵌套量词之前:假设每个“x”都代表更复杂的内容,而某些字符串同时与“x”匹配。请参阅下面的 HTML 文件部分以获取真实示例。
让我们看看当你将此正则表达式应用于 xxxxxxxxxxy 时会发生什么。第一个 x+ 将匹配所有 10 个 x 字符。第二个 x+ 失败。第一个 x+ 然后回溯到 9 个匹配项,第二个匹配剩余的 x。该组现在已匹配一次。该组重复,但在第一个 x+ 失败。由于一次重复就足够了,因此该组匹配。y 匹配 y,并找到整体匹配。正则表达式被声明为功能性,代码被运送给客户,他的电脑爆炸了。几乎。
当主题字符串中缺少 y 时,上述正则表达式会变得丑陋。当 y 失败时,正则表达式引擎会回溯。该组可以回溯到一次迭代。第二个 x+ 只匹配了一个 x,因此它不能回溯。但第一个 x+ 可以放弃一个 x。第二个 x+ 立即匹配 xx。该组再次进行一次迭代,失败下一次迭代,并且 y 失败。再次回溯,第二个 x+ 现在有一个回溯位置,将自身减少为匹配 x。该组尝试第二次迭代。第一个 x+ 匹配,但第二个卡在字符串的末尾。再次回溯,该组的第一次迭代中的第一个 x+ 将自身减少为 7 个字符。第二个 x+ 匹配 xxx。失败 y,第二个 x+ 减少为 xx,然后 x。现在,该组可以匹配第二次迭代,每个 x+ 有一个 x。但此 (7,1),(1,1) 组合也失败了。因此,它变为 (6,4),然后 (6,2)(1,1),然后 (6,1),(2,1),然后 (6,1),(1,2),然后我想你开始明白了。
如果你在 RegexBuddy 的调试器 中对一个 10x 字符串尝试此正则表达式,它将需要 2558 步才能找出最终的 y 缺失。对于一个 11x 字符串,它需要 5118 步。对于 12,它需要 10238 步。显然,这里我们有一个 O(2^n) 的指数复杂度。在 19x 时,调试器退出,因为它不会显示超过一百万步。
RegexBuddy 很宽容,因为它检测到它正在循环,并中止匹配尝试。其他正则表达式引擎(如 .NET)将永远继续下去,而其他引擎(如 Perl,在版本 5.10 之前)将因堆栈溢出而崩溃。在 Windows 上,堆栈溢出特别讨厌,因为它们往往会使你的应用程序消失,而没有任何痕迹或解释。如果你运行允许用户提供自己的正则表达式的 Web 服务,请非常小心。对正则表达式知之甚少的人在提出指数级复杂的正则表达式方面有着惊人的技巧。
独占量词和原子分组来拯救
在上述示例中,明智的做法显然是将其重写为 xx+y,该操作将完全消除嵌套量词。嵌套量词是组内重复或交替的令牌,而组本身又重复或交替。这些几乎总是会导致灾难性的回溯。唯一不会出现这种情况的情况是组内每个备选项的开头不是可选的,并且与所有其他备选项的开头互斥,并且与紧随其后的令牌(在其组内备选项中)互斥。例如,(a+b+|c+d+)+y 是安全的。如果任何操作失败,正则表达式引擎将通过整个正则表达式回溯,但它将线性地执行此操作。原因是所有令牌都互斥。它们中的任何一个都无法匹配任何其他令牌匹配的任何字符。因此,每个回溯位置的匹配尝试都将失败,导致正则表达式引擎线性回溯。如果您在 aaaabbbbccccdddd 上对此进行测试,RegexBuddy 只需 13 步即可找出结果,而不是数百万步。
但是,重写正则表达式以使所有内容都互斥并不总是可能或容易的。因此,我们需要一种方法来告诉正则表达式引擎不要回溯。当我们获取所有 x 时,无需回溯。在 x+ 匹配的任何内容中都不可能存在 y。使用 占有量词,我们的正则表达式变为 (x+x+)++y。这仅在 7 步内就使 21x 字符串失败。这是匹配所有 x 所需的 6 步,以及找出 y 失败所需的 1 步。几乎没有进行回溯。使用 原子组,正则表达式变为 (?>(x+x+)+)y,结果完全相同。
一个真实的示例:匹配 CSV 记录
以下是我曾经处理过的技术支持案例中的一个真实示例。客户试图在逗号分隔文本文件中查找第 12 项以 P 开头的行。他使用的是看起来无害的正则表达式 ^(.*?,){11}P。
乍一看,这个正则表达式似乎可以很好地完成这项工作。惰性点和逗号匹配一个逗号分隔的字段,而 {11} 跳过前 11 个字段。最后,P 检查第 12 个字段是否确实以 P 开头。事实上,当第 12 个字段确实以 P 开头时,这正是会发生的情况。
当第 12 个字段不以 P 开头时,问题就会显现出来。假设字符串是 1,2,3,4,5,6,7,8,9,10,11,12,13。在这一点上,正则表达式引擎将回溯。它将回溯到 ^(.*?,){11} 消耗 1,2,3,4,5,6,7,8,9,10,11 的点,放弃逗号的最后一个匹配项。下一个标记再次是点。点匹配逗号。点匹配逗号!但是,逗号不匹配第 12 个字段中的 1,因此该点将继续进行,直到 .*?, 的第 11 次迭代消耗 11,12,。您已经可以看到问题的根源:匹配字段内容的正则表达式部分(点)也匹配分隔符(逗号)。由于重复了两次({11} 内部的星号),这会导致大量的回溯。
正则表达式引擎现在检查第 13 个字段是否以 P 开头。它没有。由于第 13 个字段后面没有逗号,正则表达式引擎无法再匹配 .*?, 的第 11 次迭代。但它并没有就此放弃。它回溯到第 10 次迭代,将第 10 次迭代的匹配扩展到 10,11,。由于仍然没有 P,因此第 10 次迭代扩展到 10,11,12,。再次到达字符串末尾,同样的故事从第 9 次迭代开始,随后将其扩展到 9,10,、9,10,11,、9,10,11,12,。但在每次扩展之间,都有更多可能性需要尝试。当第 9 次迭代消耗 9,10, 时,第 10 次迭代可以匹配 11, 也可以匹配 11,12,。引擎不断失败,回溯到第 8 次迭代,再次尝试第 9、10 和 11 次迭代的所有可能组合。
您明白了:对于第 12 个字段不以 P 开头的每一行,正则表达式引擎将尝试的可能组合数量巨大。如果您对一个大型 CSV 文件(其中大多数行在第 12 个字段的开头没有 P)运行此正则表达式,所有这些操作将花费很长时间。
防止灾难性回溯
解决方案很简单。在嵌套重复运算符时,请确保只有一种方法可以匹配相同的匹配项。如果重复内部循环 4 次,外部循环 7 次,与重复内部循环 6 次,外部循环 2 次得到相同的整体匹配,您可以确信正则表达式引擎将尝试所有这些组合。
在我们的示例中,解决方案是对我们想要匹配的内容更加准确。我们想要匹配 11 个以逗号分隔的字段。这些字段不能包含逗号。因此,正则表达式变为:^([^,\r\n]*,){11}P。如果找不到 P,引擎仍会回溯。但它只会回溯 11 次,并且每次 [^,\r\n] 都无法扩展到逗号之外,迫使正则表达式引擎立即转到 11 次迭代中的前一次,而无需尝试更多选项。
使用 RegexBuddy 查看差异
如果您使用 RegexBuddy 的调试器 尝试此示例,您会看到原始正则表达式 ^(.*?,){11}P 需要 25,593 步才能得出结论,即正则表达式无法匹配 1,2,3,4,5,6,7,8,9,10,11,12。如果字符串是 1,2,3,4,5,6,7,8,9,10,11,12,13,仅多 3 个字符,步骤数就增加一倍,达到 52,149。不难想象,以这种指数级速度,在带有长行的较大文件中尝试此正则表达式很容易花费无限长的时间。
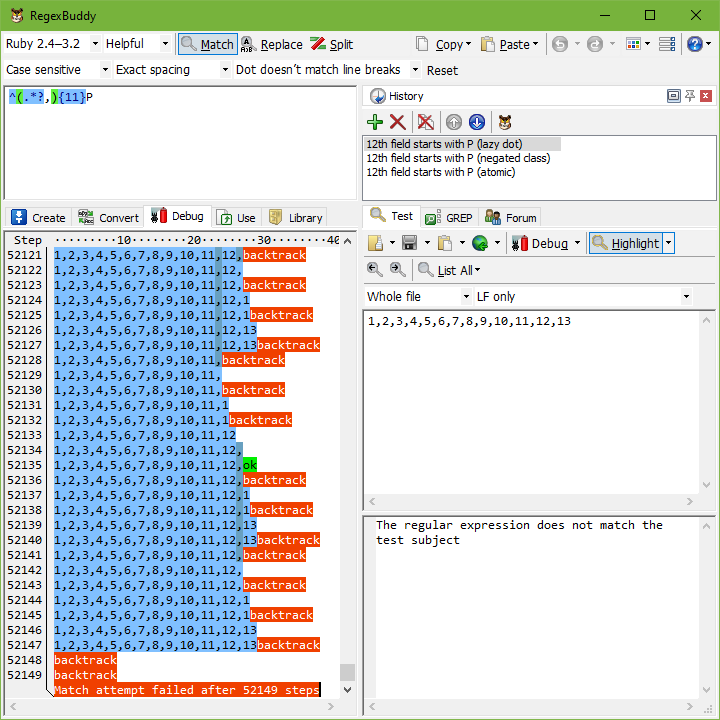
然而,我们改进的正则表达式 ^([^,\r\n]*,){11}P,无论主题字符串有 12 个数字、13 个数字、16 个数字还是十亿个数字,都只需 52 步即可失败。虽然原始正则表达式的复杂度是指数级的,但改进后的正则表达式的复杂度相对于第 11 个字段之后的任何内容都是恒定的。原因是当正则表达式发现第 12 个字段不以 P 开头时,它会几乎立即失败。它回溯该组的 11 次迭代,而不会再次展开。
改进后的正则表达式的复杂度与前 11 个字段的长度成线性关系。在我们的示例中,需要 24 步来匹配 11 个字段。只需 1 步即可发现无法匹配 P。然后需要再进行 27 步来回溯两个量词的所有迭代。这是我们能做的最好的,因为引擎确实必须扫描前 11 个字段的所有字符才能找出第 12 个字段开始的位置。我们改进后的正则表达式是一个完美的解决方案。
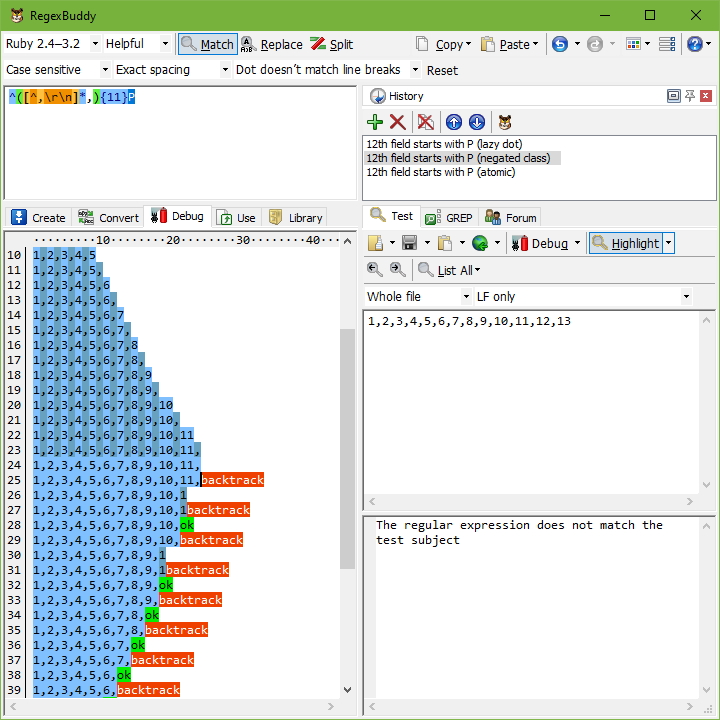
使用原子分组的替代解决方案
在上述示例中,我们可以通过更好地指定我们想要的内容,轻松地将回溯量减少到非常低的水平。但这种方式并不总能如此直接。在这种情况下,您应该使用原子分组来防止正则表达式引擎回溯。
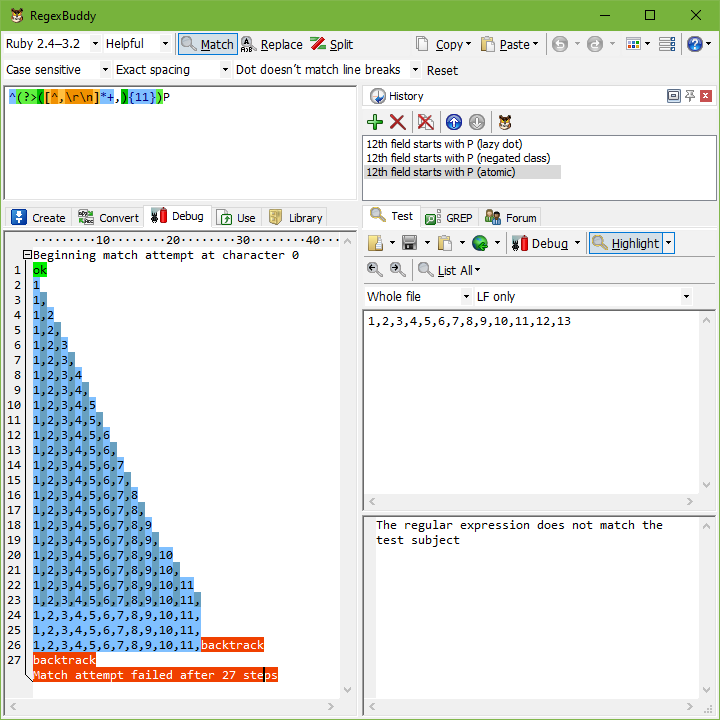
使用 原子分组,上述正则表达式变为 ^(?>(.*?,){11})P。一旦正则表达式引擎离开该组,(?>) 之间的所有内容都会被正则表达式引擎视为一个单独的标记。因为整个组是一个标记,所以一旦正则表达式引擎找到该组的匹配项,就不会发生回溯。如果需要回溯,引擎必须回溯到组之前的正则表达式标记(在我们的示例中是脱字符)。如果组之前没有标记,则正则表达式必须在字符串中的下一个位置重试整个正则表达式。
让我们看看 ^(?>(.*?,){11})P 如何应用于 1,2,3,4,5,6,7,8,9,10,11,12,13。脱字符匹配字符串开头,引擎进入原子组。星号很懒,因此最初跳过点。但是逗号不匹配 1,因此引擎回溯到点。没错:此处允许回溯。星号不占有,并且没有立即被原子组包围。也就是说,正则表达式引擎没有越过原子组的右括号。点匹配 1,逗号也匹配。 {11} 导致进一步重复,直到原子组匹配 1,2,3,4,5,6,7,8,9,10,11,。
现在,引擎离开原子组。由于该组是原子的,因此所有回溯信息都被丢弃,并且该组现在被视为单个标记。引擎现在尝试将 P 匹配到第 12 个字段中的 1。这将失败。
到目前为止,一切都像在原始的麻烦正则表达式中一样。现在出现了差异。 P 无法匹配,因此引擎回溯。但是原子组使其忘记了所有回溯位置。在字符串开头进行的匹配尝试立即失败。
这就是原子分组和占有量词的用途:通过不允许回溯来提高效率。针对我们手头问题的最有效的正则表达式将是 ^(?>((?>[^,\r\n]*),){11})P,因为星号的占有贪婪重复比回溯惰性点更快。如果可以使用占有量词,则可以通过编写 ^(?>([^,\r\n]*+,){11})P 来减少混乱。
如果您在 RegexBuddy 的调试器中测试最终解决方案,您会看到它需要相同的 24 个步骤来匹配 11 个字段。然后需要 1 个步骤来退出原子组并丢弃所有回溯信息。发现无法匹配 P 仍然需要一个步骤。但是由于原子组,回溯所有这些只需一个步骤。
快速匹配一个完整的 HTML 文件
灾难性回溯发生的另一个常见情况是尝试匹配“某物”后跟“任意内容”后跟“另一个某物”后跟“任意内容”,其中使用了惰性点 .*?。 “任意内容”越多,回溯越多。有时,惰性点仅仅是惰性程序员的一个症状。 ".*?" 不适合匹配双引号字符串,因为您实际上不想允许引号之间有任何内容。字符串不能有(未转义的)嵌入式引号,所以 "[^"\r\n]*" 更合适,并且在与更大的正则表达式结合使用时不会导致灾难性回溯。但是,有时“任意内容”确实就是那样。问题在于“另一个某物”也符合“任意内容”的条件,这给我们带来了一个真正的 x+x+ 情况。
假设您想使用正则表达式匹配一个完整的 HTML 文件,并从文件中提取基本部分。如果您了解 HTML 文件的结构,那么编写正则表达式 <html>.*?<head>.*?<title>.*?</title>.*?</head>.*?<body[^>]*>.*?</body>.*?</html> 会非常简单。在打开“点匹配换行符”或“单行” 匹配模式 的情况下,它将在有效的 HTML 文件上正常工作。
不幸的是,这个正则表达式在缺少一些标签的 HTML 文件上效果并不好。最糟糕的情况是文件末尾缺少 </html> 标签。当 </html> 匹配失败时,正则表达式引擎会回溯,放弃 </body>.*? 的匹配。然后,它将在 </body> 之前进一步扩展惰性点,在 HTML 文件中查找第二个关闭 </body> 标签。当该操作失败时,引擎会放弃 <body[^>]*>.*?,并开始一直到文件末尾查找第二个打开 <body[^>]*> 标签。由于该操作也失败了,因此引擎会继续一直到文件末尾查找第二个关闭 head 标签、第二个关闭 title 标签等。
如果您在 RegexBuddy 的调试器 中运行此正则表达式,输出将看起来像锯齿。正则表达式匹配整个文件,后退一点,再次匹配整个文件,再后退一些,再后退一些,再次匹配所有内容,等等,直到 7 个 .*? 令牌中的每一个都到达文件末尾。结果是此规则的最坏情况复杂度为 N^7。如果您通过在末尾追加文本将缺少的 <html> 标记的 HTML 文件长度加倍,则正则表达式将花费 128 倍(2^7)的时间来确定 HTML 文件无效。这不像我们第一个示例的 2^N 复杂度那么糟糕,但会导致较大无效文件上的性能非常不可接受。
在这种情况下,我们知道正则表达式中的每个文本块(HTML 标记,用作分隔符)在有效 HTML 文件中只会出现一次。这使得将每个惰性点(分隔内容)打包到原子组中变得非常容易。
<html>(?>.*?<head>)(?>.*?<title>)(?>.*?</title>)(?>.*?</head>)(?>.*?<body[^>]*>)
(?>.*?</body>).*?</html> 将匹配一个有效的 HTML 文件,其步骤数与原始正则表达式相同。好处在于,它将几乎与匹配有效文件一样快地失败于无效的 HTML 文件。当 </html> 匹配失败时,正则表达式引擎将回溯,放弃对最后一个惰性点的匹配。但是,之后就没有进一步回溯的内容了。由于所有惰性点都在原子组中,因此正则表达式引擎已丢弃其回溯位置。这些组充当“不要进一步展开”的障碍。正则表达式引擎被迫立即宣布失败。
你无疑注意到每个原子组在惰性点之后还包含一个 HTML 标签。这一点至关重要。我们确实允许惰性点回溯,直到找到其匹配的 HTML 标签。例如,当 .*?</body> 正在处理 Last paragraph</p></body> 时,</ 正则表达式标记将匹配 </ 中的 </。但是,b 将失败于 p。此时,正则表达式引擎将回溯并将惰性点展开以包括 </p>。由于正则表达式引擎尚未离开原子组,因此它可以在组内自由回溯。一旦 </body> 匹配,并且正则表达式引擎离开原子组,它将丢弃惰性点的回溯位置。然后,它将不再能够展开。
从本质上讲,我们所做的是将重复的正则表达式标记(惰性点以匹配 HTML 内容)绑定到其后的非重复正则表达式标记(文字 HTML 标签)。由于任何内容(包括 HTML 标签)都可能出现在我们正则表达式中的 HTML 标签之间,因此我们不能使用否定字符类来代替惰性点,以防止定界 HTML 标签被匹配为 HTML 内容。但是,我们可以通过将每个惰性点及其后的 HTML 标签组合到一个原子组中来实现相同的结果,并且我们确实这样做了。一旦 HTML 标签匹配,惰性点的匹配就会被锁定。这确保惰性点永远不会匹配应该由正则表达式中的文字 HTML 标签匹配的 HTML 标签。
| 快速入门 | 教程 | 工具和语言 | 示例 | 参考 | 书籍评论 |
| 正则表达式示例 | 数字范围 | 浮点数 | 电子邮件地址 | IP 地址 | 有效日期 | 数字日期转文本 | 信用卡号 | 匹配整行 | 删除重复行 | 编程 | 两个相近的单词 |
| 灾难性回溯 | 太多重复 | 拒绝服务 | 使所有内容变为可选 | 重复捕获组 | 混合 Unicode 和 8 位 |
页面网址:https://regexper.cn/catastrophic.html
页面上次更新时间:2021 年 8 月 15 日
网站上次更新时间:2024 年 3 月 15 日
版权所有 © 2003-2024 Jan Goyvaerts。保留所有权利。